


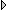

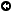
The Gaussian Integral and the Gaussian Probability Density Function
Abstract.
We review moment-generating functions to provide a context for understanding the utility of Gaussian functions and the Gaussian integral. We then explain Gaussian functions as a class of exponential function and demonstrate a common technique for integrating a Gaussian function over by converting to polar coordinates, Finally, we use a moment-generating function and the Gaussian integral to construct the parameterized form of the Gaussian or normal probability density function.
1. Characterizing Probability Distributions
Although we could start by presenting a Gaussian function and proceed by evaluating its integral over the real numbers, that would not provide a context for the exercise. The relevance of the procedure would be lost and the reader would be left with an isolated mathematical process devoid of applicability. Given that the root of Gaussian functions lies in probability theory, where a specific instance defines the so-called normal distribution, we will review the necessary statistical principles to understand the utility of the Gaussian integral.
1.1. Moments
In probability theory, a parameter associated with a probability distribution, such as its mean or variance, is said to be a characteristic of the distribution. A probability distribution is a function that models a so-called population of data points. A population is the hypothetical collection of all possible measurements made under a given set of conditions. It is a theoretical set of data and not the actual set of measurements. To distinguish the characteristics of a sample from the parameters of a distribution, we use the term statistic. Therefore, the population mean is a parameter of the probability distribution and the sample mean is a statistic of the sample set.
To illustrate the difference between a parameter and a statistic, let’s compare the formula for the expected value of a discrete random variable with probability mass function ,
| (1) |
to the formula for the expected value of a continuous random variable with probability density function ,
| (2) |
Equation 1 represents a statistic and may have different values for different sample sets. Equation 2 represents a parameter and has a fixed value. Each is a characteristic of its respective discrete and continuous distribution.
A moment is an element of a set of characteristic values that collectively describe the distribution of a random variable, albeit not in a unique manner. Under the right conditions, two random variables with identical moments will have identical probability distributions. That makes it possible to approximate the probability distribution of a random variable using moments.
In the study of statistics, moments fall into two classes: raw and central. A raw moment is computed about the origin and a central moment is computed about the mean. Without proof, we state that if is a discrete random variable with probability mass function and is a function of , then
| (3) |
and if is a continuous random variable with probability density function and is a function of , then
| (4) |
We set to find the raw moments of a probability distribution.
The raw moments of a discrete probability distribution are defined as
| (5) |
where is the moment of discrete random variable and written as . Similarly, the raw moments of a continuous probability distribution for a continuous random variable are defined as
| (6) |
The central moments are defined analogously, setting to center the moments about the mean . The central moments of a discrete random variable are
| (7) | ||||
| and for a continuous random variable they are | ||||
| (8) | ||||
Note that the first raw moment, , is equal to the mean, . The first central moment, , will always equal zero because Equation 8 reduces to for . The area under the curve to the left of the mean will always be equal to that to the right for a proper probability density function. The second central moment, , is equal to the population variance. Knowing that the population variance, , of random variable is , the variance can be expressed in terms of raw moments as
| (9) |
In addition, it is possible to define a set of moments about an arbitrary point, , in which case you would replace in Equations 7 and 8 with the point .
1.2. Moment-Generating Functions
Instead of calculating the moments of a probability distribution on an ad hoc basis, we can identify a function from which the moments can be immediately derived. This so-called moment-generating function exploits the series expansion of to create a function that, when successively differentiated at zero, produces the raw moment of a probability distribution corresponding to the level of differentiation. For example, the first derivative at zero produces the first raw moment, the second derivative the second raw moment, and so on. This works by applying Equation 4 to find the expected value of , using and integrating to yield a moment-generating function,
| (10) |
Expanding to its infinite series gives us
| (11) |
We arrive at Equation 11 by substituting terms using Equation 6.
If we differentiate with respect to we get
Evaluating at eliminates all but the first term, yielding
Taking the second derivative produces
and evaluating it at results in
It should be apparent that the derivative evaluated at produces the raw moment according to
| (12) |
As with Equation 4, if is a continuous random variable with probability density function and is a function of , then
| (13) |
We can use this formulation to find the moment-generating function of by setting . This can be useful to derive the variance directly from the second moment instead of using Equation 9. However, we will only be using raw moments.
1.3. Uniform Distribution Moments
So that we can understand how to derive the moment-generating function of the Gaussian distribution in Section 4, we will now work through the example of deriving the moment-generating function of the uniform probability distribution,
| (14) |
Applying Equation 10 to the unifrom probability density function from Equation 14, we have
Integrating gives us
which produces the indeterminate form at , requiring us to apply l’Hôpital’s rule as follows:
This gives us the complete moment-generating function for the uniform probability distribution,
| (15) |
We can now find the first raw moment of the uniform probability distribution by finding the first derivative with respect to of its moment-generating function. Using the sum and product rules, we get
The resulting function is indeterminate at , requiring us to rewrite it to produce a result of the form , allowing us to apply l’Hôpital’s rule as follows:
Swapping the terms from the last result, the first raw moment of the uniform probability distribution is
| (16) |
We can verify the first raw moment is correct by using Equation 2 to find the mean,
As a final exercise, let’s derive the second raw moment of the uniform probability distribution. Differentiating the first derivative from before, we find the second derivative is
Again, we have a function that cannot be readily evaluated at . As before, we restructure it to allow the application of l’Hôpital’s rule, giving us
Using Equation 9, we can formulate the variance of the uniform probability distribution as
| (17) |
2. Gaussian Functions
Mathematics literature uses the term Gaussian function either narrowly—using it exclusively to refer to the Gaussian probability density function—or broadly—using it to refer to a class of exponential functions. We will use the term in its broad sense, starting with the simplest instance, , before examining more complex forms. Unfortunately, the author has failed to ascertain the historical origin of Gaussian functions and how their earliest applications eventually led to the identification of the Gaussian probability density function. Therefore, we will present a pedagogical analysis of how starting from eventually leads to the Gaussian probability density function.
Generally speaking, a Gaussian function is a function whose natural logarithm is a concave quadratic function. A quadratic function is concave if its second derivative is negative. In essence, it is a downward-growing parabola as in Figure 1.
Therefore, we can define a Gaussian function as having the form , where is positive in order to ensure the second derivative of the quadratic function is negative. To simplify our discussion, we restrict our scrutiny to quadratic functions of the form , giving as our model Gaussian function. The simplest Gaussian function we can construct sets , , and , leaving us with . We plot this function in Figure 2 and show how it varies by changing the function parameters.
Starting with , we can visually note it is an even function, meaning that . This property means the function is symmetric about the -axis. More generally, all Gaussian functions are symmetric about their midpoints, with the area under the curve to the left of the midpoint being equal to the area under the curve to the right of the midpoint. We will exploit this property in Section 3 to compute half of the Gaussian integral.
The midpoint of the function can be shifted by changing the value of , as done in the plot of in Figure 2. Notice that the midpoint is shifted by an amount equal to , shifting in the positive direction when is positive and in the negative direction when is negative. Changing the value of expands or contracts the width of the curve. A value greater than one narrows the curve and a value less than one and greater than zero widens the curve, as in the plot of . Notice how the base of the curve expands by an amount equal to . The function can be stretched upward or downward by multiplying it by a constant, as in the plot of where we see that the maximum of the function changes by a factor of . The same effect can be achieved by adding a constant to the quadratic term, as in the plot of , where . But that is equivalent to multiplication by , which is one reason we chose not to use a general quadratic form for the exponent (another is that it simplifies integration by substitution as we will see in Section 4). It should be clear that and , making an additive term redundant when parameterizing the function and studying the effects of changing parameter values. In Section 4, we will see that parameters , , and posses special meanings with respect to the Gaussian probability distribution.
3. The Gaussian Integral
Recognizing that ranges in value from to , suppose we wanted to use a Gaussian function as a probability density function. Our first step would be to ensure that the integral over is equal to . We would have to integrate the function to determine the area, , under the curve. If , we would normalize the function to so that its integral over equaled . We will, in fact, do all of this while deriving the Gaussian probability density function. However, embarking on this journey requires evaluating the Gaussian integral, for which we must first take a brief detour.
Solving problems in mathematics often requires what could be called tricks; like when we restructured the derivatives in Section 1.3 so we could apply l’Hôpital’s rule. The Gaussian integral can be solved in various ways, all of which require some trickery. We will be using two tricks, the first of which is based on the seemingly trivial identity , allowing us to observe that
| (18) | ||||
| implies | ||||
| (19) | ||||
The second trick we will use is to convert from Cartesian to polar coordinates, for which the reader will have to refer to a calculus textbook if the process is unclear.
We wish to evaluate the improper integral
to see if the integrand can be adapted for use as a probability density function. We cannot evaluate the integral based on an existing indefinite integral because the integrand has no elementary indefinite integral. To evaluate the improper integral will depend exactly on its improper nature, integrating from negative to positive infinity. First, we apply Equation 18 to rewrite the integral as
Next, we replace one of the dummy variables with another dummy variable, , allowing us to rewrite the integral as the following double integral:
For clarity, we’ll set aside the square root until the end and evaluate the double integral by converting to polar coordinates as follows:
Now we can apply the square root to arrive at our final result,
| (20) |
The various transformations we performed were possible because is a continuous function. As noted in Section 2, holds true for a Gaussian function. That allows us to infer that
| (21) |
More formally, if is continuous on the interval containing point then
This property of improper integrals allows us to write
Observing that gives us
4. The Gaussian Probability Density Function
Having evaluated the most basic Gaussian integral as , we can start to build a probability density function derived from the simplest Gaussian function, , normalizing it to so that its integral over evaluates to . To investigate whether this is a useful construction, we can derive its moment-generating function and first two raw moments. Using Equation 10, we have
| Using and , we find | ||||
Note that we used Equation 20 to evaluate via substitution.
We now use Equation 12 to find the first two raw moments. The first raw moment is
A mean of is exactly what we would expect for a probability density function centered about the origin. The second raw moment is
giving us a variance of
after using Equation 9.
The values of the raw moments we found are constants that don’t really help us toward formulating a general Gaussian probability density function. But they do give us clues about how such a function might be formulated. In Section 2, we saw how the center of a Gaussian function could be shifted by changing the value of the parameter in . We now have a clue that is the mean of the distribution because it lies at the midpoint about which the function has symmetric areas. The parameter may be related in some way to the variance, given how it affects the width of the curve. The parameter must be a normalizing constant. To test our theory, we can hold these parameters constant, with being positive, and try to find a moment-generating function parameterized in terms of , , and .
We already know that does not affect the area under the curve. Therefore we will ignore it and evaluate the integral of over to find a value of dependent on that normalizes the function. That will enable us to find a moment-generating function for the function including using substitution as we did earlier. Using our earlier work, we can readily evaluate the integral as follows:
| where and . Substituting Equation 20, we get | ||||
| Solving for in | ||||
| to normalize the function leaves us with | ||||
| (22) | ||||
Now we can use as a probability density function and find its moment-generating function. Starting with
| we can substitute and to get | ||||
The first moment is
As we suspected, is equal to the mean, . The second moment is
We can now find the variance using Equation 9 as
Solving for in terms of produces
Substituting this value into Equation 22 gives us
Replacing , , and in with their parameterized values produces the probability density function for what is known as the Gaussian or normal distribution,
| (23) |
Notice how Equation 23 is dependent on the mean, , and the standard deviation, . As mentioned previously, changing just moves the center of the distribution left or right. But controls both the width and the height of the distribution. When the distribution widens, it gets shorter. When the distribution narrows, it gets taller. The role of is to constrain the area under the curve to remain constant independent of the value of . Therefore, the Gaussian probability density function represents a family of functions of unit area.
When and , the distribution corresponding to the probability density function is called the standard normal distribution,
| (24) |
The standard normal distribution’s probability density function is used primarily as a reference function for numerically integrating probabilities that can be scaled to calculate probabilities for other normal distributions based on the value of . The probability within standard deviations of the mean is the same for all normal distributions regardless of the value of . Therefore, calculating probabilities for the standard normal distribution allows you to determine them for any normal distribution as long as you express your ranges in relative terms of standard deviations from the mean instead of using absolute numbers.
5. Commentary
The Gaussian probability density function is usually presented as a formula to be used, but not ncessarily understood. Although we attempted to show a step-by-step process from which one can get from to Equation 23, we did not explain the origin of . Also, we cheated and chose as an exponent instead of with little explanation. At this point, it should be apparent that we needed the exponent to be in the form of a square paralleling so that we could integrate by substitution.
Ultimately, our goal was to show that the Gaussian probability density function did not sprout out of thin air fully formed. Instead, it evolved from a series of observations about the family of functions derived from . The Gaussian integral formed the core of our exercise because we only needed to evaluate it once and were subsequently able to use it multiple times via substitution, demonstrating its utility.
The Gaussian probability distribution occurs frequently in many contexts as a result of the central limit theorem.
The Central Limit Theorem.
Given a random sample of independent and identically distributed random variables from a distribution with finite mean and finite variance , let
| Then | ||||
In other words, the distribution function converges to the standard normal distribution from Equation 24 as .
For large —usually greater than —one can pretend that is distributed according to the normal distribution when calculating probabilities such as . This should not be done recklessly, but does work in many situations. We will not prove the central limit theorem, but familiarity with it goes a long way to understanding why it is so common for textbooks to assume a Gaussian distribution in various contexts.
As a final comment, we explored Gaussian functions and the Gaussian probability distribution function in one dimension. The functions can can be extended to multiple dimensions, where analysis becomes considerably more complicated than what we have explored.
6. Addendum
For completeness, we have decided to demonstrate how to evaluate the integral of over the real numbers and summarize the integrals we covered in this paper for easy reference.
6.1. General Gaussian Integral
After evaluating the integral of the exponential function of a general concave quadratic function, it should be possible to evaluate the integral of any Gaussian function by simple parameter substitution. As before, the integral will depend on already having arrived at the result of Equation 20 and completing the square to allow integration by substitution as follows:
| substituting and to get | ||||
6.2. Summary of Gaussian Integrals
We now summarize the results of evaluating the Gaussian integrals in this paper:
| and | ||||
All you really need is the final identity, from which all the others can be derived by substituting the appropriate values for the equation’s parameters. Note, however, that we needed to evaluate the first integral in order to evaluate all of the others.